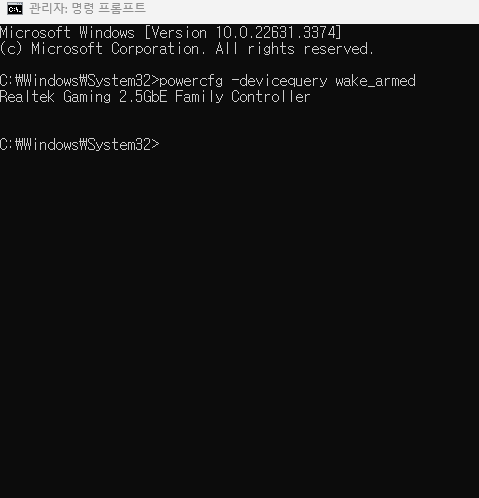
E:\source\install.esd 는 바로 위에서 다운받은 설치 미디어 파일이 있는 드라이브다. iso를 다운받아 마운트 시키지 않고 압축을 풀어도 되는데, 여튼, 설치 미디어의 source 폴더 밑에 install.esd 가 있는 것을 확인할 수 있다. 3메가 정도 파일이다.
그리고,
/sourceIndex:3
에서 3번 인덱스는 win pro 버젼을 가리킨다. 경우에 따라 pro 버젼이 아니거나 인덱스가 달라질 수도 있는데, 그 인덱스는 역시 명령프롬프트에서 아래의 명령어로 확인하면 된다.
윈도우 원격 데스크톱으로 작업하다보면, 종종 호스트 컴퓨터의 인터넷 접속속도가 느려질 때가 있다. 그로 인해 호스트 컴퓨터의 화면이 부드럽게 넘어오지 못하는 등 여러가지 불편을 겪기도 한다.
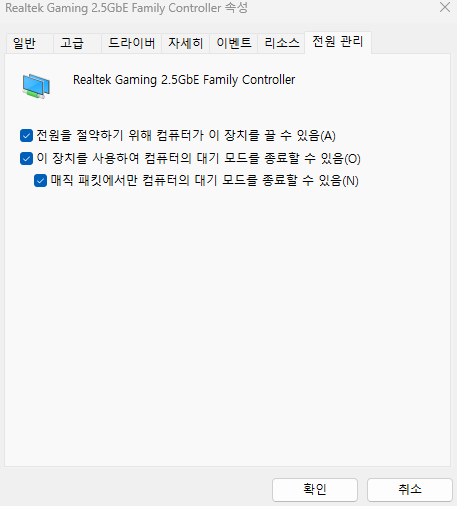
랜카드의 설정을 바꾸어 이 문제를 해결해보자.
1. 문제 발생
내가 이용하는 환경은 호스트 컴퓨터와 클라이언트 컴퓨터 모두 KT의 500Mbps 플랜을 사용중이며, 양쪽 모두 4k 모니터를 사용한다.
이 플랜의 경우, 네트워크 속성에서 조회해보면 링크 속도(송신/수신)가 1000/1000 Mbps로 표시가 된다.
그런데, 원격접속시 종종 호스트 컴퓨터의 이더넷 접속속도가 10/10 Mbps로 떨어질 때가 있다. 원인은 잘 모르겠다.
일반적으로 사용하는 모니터가 1920 x 1080 해상도라고 할 때, 원격 데스크톱은 네 배 크기의 화면 이미지를 압축해서 보내주어야 하므로 대략 네 배 정도의 대역폭이 필요하다.(항상 화면의 모든 부분을 업데이트 하는 것 같지는 않으므로 아마도 네 배 보다는 적을 것이다)
정상적인 속도에서는 큰 불편함이 없지만 접속속도가 낮아지면 화면이 부드럽지 못해 여간 불편한 것이 아니다.
2. 간단하지만 말도 안되는 방법
호스트 컴퓨터의 이더넷 속성에서 "사용안함"을 하면 인터넷이 끊긴다.
그리고 아이콘이 회색(비활성화)으로 변해서 접속이 끊긴 것을 확인했으면 다시 "사용함"으로 바꾼다.
이 방법의 최대 단점은, 접속이 끊기는 순간 원격 데스크톱도 (당연히) 종료되고,
누군가 호스트 컴퓨터 앞에 앉아 "사용함"으로 바꾸기 전에는 다시 접속할 방법이 없다는 점이다.
3. 쉽게 할 수 있지만 매번 번거로운 해결 방법
이 때, 원격 접속 상태로 호스트 컴퓨터를 재부팅하면 된다.
죄를 지었으면 죄부팅을 해야겠지.
당연히 자동적으로 원격접속이 끊길 것이고, 호스트 컴퓨터가 재부팅 될 때 쯤 다시 원격 접속을 하면 링크 속도가 정상으로 되돌아간다.
단점은 사용하던 프로그램을 모두 닫아야 한다는 점.
그리고 재부팅 후 약간 뒤에 또 접속 속도가 떨어진다는 점
그리고 만에 하나, 재부팅하면서 그 순간에 호스트 컴퓨터의 IP가 변하면 다시 접속할 수가 없다.(이런 일은 거의 일어나지 않는다)
이런 재부팅이 귀찮았던 차에 혹시나 해서,
cmd 창에서 ipconfig /renew 등으로 해결을 시도 해보았지만 링크 속도는 변하지 않는다.
매번 이렇게 문제를 해결하다가 너무 소모적인지라, 맘먹고 이것 저것 시도해보고 찾던 도중 드디어 해결을 했다.
구글링 해봐도 잘못된 정보들도 많고 정확히 설명해주는 사람이 별로 없다. 유투브에는 경험적으로 비교한 영상만 볼 수 있다.
벤치마크도 몇개 나오는데, 벤치마크 역시 몇 가지 정해진 프로세스를 돌리는 것인지라 핵심을 짚지 못하는 것 같다.
보통 사람들이 알고 있는 점들은 다음과 같다.
"동일 가격대 기준으로 게임에서는 지포스가 빠르고 전문가용 그래픽 소프트웨어에서는 쿼드로가 빠르다"
분명 이 문장은 맞는 부분도 있지만 깔끔하게 모든 내용을 설명해주지는 못한다. 전문가용 그래픽 소프트웨어라도 엔비디아에서 별도의 드라이버를 지원해 주지 않는 어플리케이션은 쿼드로의 장점이 없다. 다수의 쿼드로 카드는 GTX에 비해 "소프트웨어적으로" 차별화 되어 있기 때문이다.
그렇다면 하드웨어는 같을까? 다수의 쿼드로 카드의 경우 거의 그렇다고 볼 수 있다.
카드를 구매하려는 입장에서 무엇을 사야 할까?
1. 게임을 주로 한다.
"지포스"
이건 이미 알고 있겠지만, 지포스 계열을 사면 된다.
FP32 계산 유닛 Cuda Core 수가 중요하다.
정확한 표현으로 Cuda Core는 정수 연산 코어, 단정밀도(single precision, FP32), 배정밀도(FP64, double precision) 모두에 해당하지만
대부분의 경우 "쿠다 코어 수 3,584개"라고 하면 FP32 계산 유닛 수를 가리킨다.
GTX 1080 Ti 의 경우 3,584개이며, RTX 2080 Ti의 경우 4,352개다.
물론, VRAM도 관련이 없는건 아니지만, 게임 개발자는 그 시대에 생산되는 그래픽카드를 염두에 두고 개발하게 되므로 소비자의 입장에서 VRAM은 신경쓰지 않아도 된다.
2. 영상 작업을 주로 한다.
"지포스" or "cpu"
자신이 사용하는 코덱이나 인코더가 OpenCL이나 Cuda 가속을 지원할 경우, 지포스 계열을 사면 된다.
만약 선호하는 코덱이나 인코더가 이 두가지를 지원하지 않는다면 cpu 성능에 의존하므로 cpu에 돈을 투자해야 한다.
쿼드로, 지포스 모두 쓸모가 없다는 말이다.
3. 포토샵 같은 2D 어플리케이션을 사용한다.
"지포스"
포토샵을 주로 사용한다면 지포스 계열을 사면 된다. 물론 쿼드로가 메모리 전송 속도가 다소 크긴 하지만 눈에 띄는 이점이 없다.
포토샵은 주로 cpu 성능에 의존하지만 여러가지 계산에서 점점 gpu를 이용한다. 어도비 공홈에서 어떤 명령어가 gpu 의 영향을 받는지 설명해주고 있다.
"3D가 아니면 그래픽카드에 투자할 필요 없다. cpu에 투자하라"는 옛 말이다. 점점 gpu 성능을 이용하는 명령어들이 많아지고 있다.
그리고,
검색을 하다 보면 간혹 Quadro만 10bit 컬러를 지원하고 게임용카드인 Geforce는 8bit 컬러를 지원한다는 내용도 나온다.
그런데 이것은 분명히 잘못된 정보다.
10bit 컬러 포맷이라는건 채널당 10bit, 즉 R, G, B, A 각각 1024 단계의 색상을 사용한다는 것이고, 8 bit는 256단계의 색상을 사용한다는 말이다.
결국 이건 메모리를 어떻게 나누어 쓸 것인가에 대한 문제이므로 쿼드로/지포스와는 무관하다. 오히려 드라이버의 지원과 관계있다.
OpenGL이나 DirectX 등의 드라이버 수준의 단계에서는 카드 가리지 않고 10bit 모두 지원한다. 단, 포토샵 같은 어플리케이션이나 자체 이미지 포맷에서 몇 bit까지 제어할 수 있도록 지원하는가가 중요하다. (Adobe Lightroom 같은 어플리케이션에서 RAW 포맷을 지원하는 것 처럼)
그리고, 당연히 10bit 단계의 색상을 눈으로 모두 보려면 모니터가 이를 지원해야 한다.
참고로 DirectX는 잘 모르겠는데, OpenGL의 경우에는 채널당 10bit는 물론이고 무려 32bit 이미지 포맷을 텍스쳐와 이미지 모두 지원한다.
glTexImage2D라는 OpenGL명령어는 해당 명령어와 관련하여 다루게 될 이미지 포맷을 정의한다. 아래 표에서 GL_RGBA32F와 GL_RGBA32UI가 바로 128bit 이미지 포맷이다. (Red, Green, Blue, Alpha 각각 32bit)
4. 3D 어플리케이션을 사용한다.
"2019년 기준으로는 그래도 지포스!!!!!"
"Cuda Core 가 몇개를 확인하고 살 것. 코어 수에 성능이 비례한다고 보면 된다"
캐드나 3dsMax, Rhino3D 등 특정 어플리케이션을 주로 쓴다면, 자신이 사용하는 어플리케이션이 Quadro의 지원을 받는지 검색 등으로 찾아보자. 지원받지 않는다면 똑같다. 메모리 대역폭 말고 칩이 근본적으로 같기 때문이다. (Quadro P6000 와 GTX 1080 Ti 의 경우).
그리고 아마도, 차별점을 찾기 어려울 것이다. 적어도 2019년 현재로서는.
과거에, 그러니까 예를 들어 2003년 정도 기준으로 설명하자면 분명히 두 라인업의 하드웨어 차이가 존재했다.
NV35 칩을 사용한 Geforce FX 5900 Ultra와 Quadro FX3000G를 비교해보자. 페이지 하단의 표를 살펴보면 쿼드로의 경우 NV35 GL 이라는 다소 이형의 칩을 사용하였다는 점을 알 수 있고 ROPs 가 8개 지포스의 두배다. ROP는 Rendering OutPut unit의 약자로서, OpenGL 그래픽 파이프라인의 마지막 단계에서 화면에 뿌려주는 프래그먼트 셰이더와 관련된다. NV35GL 칩은 이 ROP를 지포스에 비해 두배 보유함으로서 양면 렌더링이나 더 많은 샘플링을 이용한 안티에일리어싱을 하드웨어적으로 지원할 수 있었던 것 같다. 픽셀 처리 성능이 두배이므로 대략적으로 말이 된다.
당시의 두 라인업 비교 공식 문서는 다음의 pdf를 참고하자.
http://www.nvidia.com/object/quadro_geforce.html
이러한 하드웨어 차이로 인해, 엔비디아는 뷰포트 드로잉 가속 기술에 대한 OpenGL 확장 명령어를, 특정 소프트웨어에 대한 별도의 쿼드로 드라이버에서만 지원했었다. 이러한 기술 지원 정책이 있었던 탓에 하드웨어의 전반적인 성능이 낮았던 과거에는 쿼드로에 돈을 투자할 만한 가치가 있었지만, 요새는 약간 달라진 것 같다.
일단 하드웨어의 차이가 없다. Quadro P6000과 GTX 1080 Ti를 놓고 보면 똑같은 GP102 칩셋을 사용한다.
칩셋 크기는 똑같은데 내부의 SM을 모두 활용하느냐, 아니면 몇 개를 사용하지 않느냐에 따른 SM 유닛 개수 차이로 인해 쿠다 코어 및 전반적으로 쿼드로측이 약간 우세하지만(3840 vs 3584), 딱 그 뿐이며 지원 명령어는 차이가 없는 것 같다.
그래서 예를 들어 "autocad performance quadro vs geforce" 와 같이 특정 어플리케이션에 대해 검색해보면, 사용자들이 두 카드를 비교해놓은 결과를 볼 수 있는데 "과거에는 차이가 있었지만 최근에는 차이가 없다"라는 것이 중론이다.
심지어 어떤 사람들은, "차이가 없는데, 이것에 대해 언급하는 것이 금기시 되어 있는 것 같다"라고도 써 놓았다. 엔비디아 공식 홈페이지에서는 정보를 찾기 어렵기 때문이다. (https://forums.autodesk.com/t5/autocad-architecture-forum/graphics-card-debate-geforce-vs-quadro/td-p/5568485)
그렇게 볼 때, GTX 1080Ti 같은 고가의 지포스 카드는 충분히 메리트가 있다.
같은 GP102 칩을 사용한 Quadro P6000 과 비교할 때 GTX 1080Ti는 엔비디아 공홈 기준 가격이 7배 정도 차이나기 때문이다.
게다가 예를 들어 Rhino3D Vray의 실시간 뷰포트 RT 렌더링같은 경우 Cuda 코어를 사용해 연산하기 때문에 쿠다코어 수가 많은 카드를 사는 것이 절대적으로 유리하다.
만약 당신이 큰 회사의 컴퓨터 담당자고, 단지 몇 대에 한하여 PC를 구성해야 한다면 그냥 고민없이 쿼드로를 구입하면 된다. 몇 백만원 아꼈다고 칭찬받을 일 없다.
스스로의 컴퓨터를 구성한다고 지포스를 구매하길 권장한다. 쿼드로가 성능은 근소하게 앞서지만 고가의 지포스 계열도 꽤 괜찮은 성능을 제공하기 때문이다. 동일 가격대라면 두 말할 필요도 없다.
이 링크를 한번 보자. https://www.youtube.com/watch?v=JtX5o-MlyaU
2016년 당시 비슷한 가격대인, 구형 쿼드로와 신형 지포스를 비교했다.
보통의 학생이라면 무조건 지포스를 추천한다.
5. WebGL이나 VR 등을 즐긴다.
"지포스"
동일 가격 기준으로 할 때, 무조건 GTX다.
이 경우도 결국 FP32 cuda 코어 수가 중요하다.
두 카드 모두 가지고 있을 경우 http://david.li/fluid/ 등에서 테스트해보면 된다.
6. 배정밀도(FP64) 계산을 주로 한다.
"다른 기준으로 보자"
Geforce 나 Quadro의 기준으로 보지말고 gpu의 칩이 무엇인지 확인해야 한다.
사실, 이쯤 되면 당신은 아마도 이 글을 참고하지 않고 스스로 GPU chip 다이어그램을 보고 판단할 수 있을 것 같다.
GPU 설계의 기본 단위인 SM을 보면, 정수연산 유닛, 단정밀도 유닛, 배정밀도 유닛이 몇개 있는지 알 수 있다.
Volta Architecture의 GV100 칩을 사용한 Quadro GV100이나 Titan V 같은 경우 FP64 연산 유닛과 FP32 유닛이 1:2의 비율로 들어가 있다. Pascal Architecture의 GP100칩을 사용한 Quadro GP100 이나 Tesla P100의 경우도 역시 1:2의 비율이다. 배정밀도 성능이 단정밀도의 1/2까지 올라간다.
참고로 GP102를 사용한 Quadro P6000이나 GTX 1080Ti는 똑같이 FP64 유닛이 매우 적다. 계산성능이 단정밀도의 1/32에 불과하다.
쿼드로나 지포스의 비교 관점으로 보지 말고, 새로운 Turing Architecture 가 적용된 카드를 사면 된다.
지포스라면 RTX 2080 Ti가 있겠다.
8. 서버에 다수의 컴퓨터를 구성한 후 VGA를 꽂아서 성능을 극대화하고자 한다.
"QUADRO"
Quadro가 좋다.
RDMA 방식을 사용하여 서로 다른 컴퓨터의 카드 간에 데이터를 복사할 때 cpu를 거치지 않고 VRAM 에서 곧바로 VRAM으로 가는지 확인해보면 된다.
컴퓨터 한 대 안의 멀티 VGA의 경우 쿼드로의 장점이 없지만, 컴퓨터가 여러대라면 쿼드로가 확실한 우위를 가진다.
사실 이 경우도 이런 글을 참고로 하지 않고 좀 더 전문적인 지원을 받을 것이라 생각한다.
여기에 기본적인 설명이 있다.
https://developer.nvidia.com/gpudirect
이번에는 두 라인업의 차이를 비교해서 몇 가지 적어보았다
내용은 위와 약간 중복되지만 다른 관점에서 서술한 글임을 참고하자.
1번부터 5번은 지포스 GTX 1080 Ti와 QUADRO P6000을 염두에 두고 썼다.
1. 기본 설계가 같다. 쿠다 코어 수가 같다.
두 카드 모두 Pascal Architecture다. SM구조가 동일하다.
FP32 쿠다 코어 수가 3,584개로 같다. FP32 쿠다 코어는 GPU연산의 핵심이다.
2. VRAM은 다르다.
1080Ti 는 11기가, P6000은 24GB로 쿼드로가 두 배 이상이다.
쿼드로는 ECC램을 사용한다는 정보도 있다.
램에 있어서는 분명히 쿼드로가 좋다. 더 많은 데이터를 GPU 램에 올려놓고 작업할 수 있다. VRAM이 절대적으로 아쉬운 사람은 쿼드로를 구입해야 한다. host ram(본체 메모리)에서 device ram(VGA 메모리)으로 자주 복사하는 작업은 상대적으로 시간비용이 많이 들고, 램 자체도 gpu 쪽이 빠르다.
그렇지만 가격이 네 배 이상 차이난다는 점을 항상 잊지 말자.
3. 쿼드로는 윈도우 원격 데스크톱 접속시 OpenGL 실행이 가능하다.
지포스 계열은 windows RDP 접속시 OpenGL 실행이 안된다. 물론 매번 불편하지만 이걸 극복하는 방법도 있다. ( steelblue.tistory.com/10 )
즉, 하드웨어의 근본이 크게 다르지 않기 때문에, 저항을 조작하여 훨씬 저렴한 지포스를 쿼드로로 인식시켜 드라이버를 깔고 사용하는 사례들도 10년 전부터 있었다.
5. WebGL을 사용하는 웹페이지에서 저가의 Quadro는 극악의 성능을 보여준다.
예를 들어 쿼드로 P620 같은 경우 파스칼 아키텍쳐로서, 램 2기가에 쿠다코어 512개다.
한물 간 지금은 다나와 최저가로 22만원인데, 한창때 26만원이었다.
그런데, 13만원 정도의 GTX 1050 의 쿠다코어도 640개다.
쿠다 코어 수는 gpu 연산의 핵심이다. 예를 들어 http://david.li/fluid/ 같은 사이트에 접속해서 두 카드로 시뮬레이션 해 보면 쿼드로가 상대적으로 느린 것을 육안으로 확인할 수 있다.
6. 마찬가지로, Cuda 코어 수가 핵심인 GPU 연산에서 동일 가격대의 지포스는 QUADRO 보다 절대적 우위에 있다.
쿼드로 계열의 고가 가격정책 때문에 100만원의 예산으로 그래픽 카드를 살 때, 지포스는 GTX 1080 Ti를 살 수 있고 쿼드로는 P4000 정도를 살 수 있다. 쿠다코어는 GTX가 딱 두 배 많다.(3584 vs 1792) 게임에서나, GPU 연산을 필요로 하는 분야에서나 당연히 GTX를 사야 한다. 딥러닝 연구자들은 이런 점을 알기 때문에 GTX 1080Ti나 RTX 2080 Ti를 찾는다.
7. 엔비디아가 쿼드로 페이지에서 강조하는 OpenGL 확장은 지포스도 지원한다!!
그렇다면, VRAM용량을 제외하고 쿼드로가 차별화된 점은 과연 무엇인가?
세세한 하드웨어적 차이점은 잘 모르겠다. 좀 더 고가의 안정적인 부품을 썼을 수도 있고, 잘 뽑힌 칩을 우선적으로 배정했을 수도 있다.
확실한 부분은 소프트웨어적으로 쿼드로만 지원하는 경우가 있긴 있다는 점이다.
엔비디아 자체적으로 지원하는 OpenGL 확장 명령어의 경우, 몇 가지 조회해보면 쿼드로만 지원하는 경우가 있다.
여기서 설명을 보면 쿼드로의 벤치마크만 있지만, 해당 OpenGL 확장들은 지포스 드라이버에서도 지원한다.
예를 들어 오토캐드 개발자들이 OpenGL로 개발을 할 때 해당 명령어를 사용하여 뷰포트 렌더링 구현을 한다면 그대로 실행될 수 밖에 없다. 지포스도 똑같이 빠르다는거다.
참고로 bindless graphics 에 대해 부연하자면, ( https://www.nvidia.com/object/bindless_graphics.html )
OpenGL로 코드를 작성할 때, 1초에 60프레임을 그린다면, 매 프레임마다 cpu에서 gpu로 명령을 내려서 그린다.
이것을 어떤 방식으로 그리느냐에 따라서 그리기 속도가 굉장히 차이가 많이 난다.
예를 들어 백만개의 삼각형을 그릴 때, cpu에서 백만번의 drawcall을 gpu로 보낸다고 생각하면 어마어마하게 느리다. 1초에 1프레임도 안나올 것 같다.
그래서 보통은 삼각형을 그룹지어서 drawcall 하거나, 좌표와 인덱스를 미리 vram으로 보낸 뒤에 한번의 drawcall로 그리기도 한다.
이 때 cpu에서 drawcall을 보낼 때 사용하는 트리거 역할의 변수와 vram에 저장되어 있는 데이터의 주소를 binding 한다고 표현하는데, bindless라는건 gpu의 vram 주소들 목록에 (바인딩 없이)직접 엑세스 해서 drawcall 할 때 cpu와 gpu 사이에 왔다갔다 하는 작업을 최소화 하자는 거다.
텍스쳐 매핑의 경우에도 구현하는 명령어가 있다.
더불어,
2018년에 엔비디아에서 새로 출시한 RTX 카드의 경우에는 새로운 튜링 아키텍쳐의 적용으로 OpenGL에서 Mesh Shader 를 사용할 수 있게 되었다. 이게 무엇인고 하니, 기존의 OpenGL 파이프라인은 버텍스 셰이더부터 프래그먼트 셰이더까지 거치는 동안 모든 데이터들이 고정된 함수들을 나란히 통과해야 했기 때문에, 불규칙한 형상에서 다른 복잡도의 데이터들이 전송되어 병렬 처리 작업을 할 때 복잡한 쪽의 시간에 맞추어진다는 단점이 있었다. 그런데 튜링 아키텍쳐의 Mesh Shader는 Task Shader와 더불어 기존의 버텍스 셰이더, 테셀레이션 세이더, 지오메트리 셰이더 등 버텍스 처리 부분을 대체시키고, 한쪽의 작업이 끝나면 다른 쪽의 작업을 할당하도록 상호 유연하게 협력하도록 실행된다.
이 메쉬 셰이더의 기본적인 특징과 더불어 컬링이나 버텍스 재사용 등 다른 알고리즘을 결합시켜, 로딩된 메쉬들을 확대할 경우 기존 방식보다 프레임이 두배 혹은 그 이상 향상된다. 엄청난 성과다.
이것 역시 당연히 모든 RTX 계열(지포스와 쿼드로 포함)에서 해당 코드를 실행할 수 있다. 지포스나 쿼드로 마찬가지다. 튜링 아키텍쳐 칩이라면 가능하다.
8. 물론 특별하게 차별화된 QUADRO도 있다. 그런데 이건 지포스 vs 쿼드로의 관점이 아니다.
Volta Architecture의 경우 배정밀도(FP64, double precision)의 코어가 FP32의 절반이나 들어가 있다.
따라서, 볼타 아키텍쳐로 제작된 Tesla V100, Quadro GV100의 배정밀도 부동소수점 연산 능력은 같은 세대의 GTX나 일반적인 Quadro 보다 10배 이상 높다.
Quadro GP100 이나 Tesla P100 은 GTX 1080 Ti 와 동일한 Pascal architecture 계열이지만 FP64 계산능력은 역시 10배 이상 높다. 동일 세대지만, GTX1080Ti 나 Quadro P6000 은 FP64 cuda core수가 현저히 적은 GP102 칩을 썼고, Tesla P100이나 Quadro GP100은 FP64 Cuda Core가 FP32의 절반까지 들어간 GP100 칩을 사용했기 때문이다.
배정밀도 연산을 필요로 하는 사람이라면 Volta Architecture 등 스스로 찾아서 특별한 카드를 구매하면 된다.
같은 architecture라고 가정했을 때, 쿼드로의 장점은 어디까지나 몇개의 한정된 3d용 응용 소프트웨어의 작업화면 상에서의 실시간 디스플레이까지다.
렌더링 성능은 cpu나 쿠다코어 수에 의해 좌우된다.
30만원 정도의 GTX 1060 의 경우에도 과거에 비해 디스플레이 성능이 매우 높아졌기 때문에 웬만큼 복잡한 화면은 견뎌낸다.
같은 예산으로 컴퓨터를 맞춘다고 할 때, 게임을 전혀 안하더라도, 점점 높은 쿠다코어를 활용하는 경우가 많아지기 때문에 동일 가격대의 쿠다코어가 현저히 적은 쿼드로 계열을 사는 것은 추천하고 싶지 않다. 예를 들어 영상 인코딩 시 OpenCL을 사용하거나 WebGL 페이지를 보거나 하는 경우다.
요새는 이 실시간 디스플레이도, 예를 들어 vray의 경우 GPU연산을 이용하여 레이트레이싱 결과물을 뽑아주는 경우도 있는데, 이것은 위에서 서술한 쿼드로 지원과 또 다른 얘기다. 순전히 쿠다코어 연산에 의존하기 때문에 쿼드로의 이점이 전혀 없다고 보면 된다.
코딩을 하다보면 성능이 좋고 데이터가 저장되어 있는 PC를 서버로 두고, 외부에서 클라이언트로 접속해 서버 컴퓨터의 코드를 실행시켜야 할 경우가 있다. 물론 데이터의 용량이 작고 구동이 가벼울 경우 온전히 복사하거나 클라우드 동기화를 통해 직접 눈 앞에 있는 컴퓨터로 실행시키면 그만이지만, 그렇지 못한 경우도 있다.
예를 들어 몇기가의 데이터를 읽어서 OpenGL로 구동시켜야 할 경우에는 클라우드 동기화보다는 원격 접속이 편하다.
그런데 문제가 있다. 윈도우 원격 데스크톱을 활용한 원격 접속의 경우에는 OpenGL이 1.1 버젼까지만 구동가능하므로 대부분 에러를 내뱉고 실행되지 않는다.
해결 방법은 여러가지가 있다.
1. windows RDP 대신 다른 원격 접속 프로그램을 사용한다. (어떤 것에서 OpenGL이 실행 되는지는 확인하지 못했다)
2. 엔비디아 vga 기준으로 할 때, Quadro 계열을 구입한다.
엔비디아에서는 GTX나 RTX 계열의 vga를 꽂은 PC에 원격 접속을 할 때, OpenGL의 사용을 막아놓았다. 그런데 쿼드로 계열은 된다. 당연히 소프트웨어적으로 막아놓은 것이라 엔비디아에서 풀어주면 되는데 그렇게 하지 않는다. 다른 어떤 이유가 있는지는 모르겠지만 여하튼 지원하지 않는다.
그렇지만 cuda core 기준으로 볼 때, 같은 쿠다코어 수의 vga를 구입하려면 가격이 다섯배 이상 뛰므로 추천하지 않는다.
3. 그래서 해결방법은 다음과 같다.
요약해서 말하자면 원격 접속을 끊고, 기본 계정 상태에서 코드를 실행시킨 뒤 다시 원격 접속하는 방법이다. 그러면 OpenGL 창이 떠 있을 것이다!!!
그러면 그걸 어떻게 할까?
아래의 코드로 .bat 파일을 만들어 "관리자 모드"로 실행하면 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
@echo off
echo.
echo Remote Desktop will be temporarily disconnected . . . please reconnect after a few seconds.
echo.
pause
@echo on
REM The active session has an arrow as the first character
OpenGL 코드를 작성할 정도면 그 밖의 궁금한 부분은 스스로 해결 할 수 있을 것이라 생각한다.
예를 들어 실행했을 때, dll을 못찾는다거나 등등의 부분은 bat 파일에서 exe를 실행시키기 전에 디렉토리를 변경하거나 필요한 부분을 path에 등록하는 방식 등으로 해결할 수 있다.
*.
처음에 원격 접속으로 OpenGL 실행이 되지 않았을 때 의구심이 들었던 부분이 있었다.
코드와 데이터가 있는 PC에서 opengl 코드를 실행시켜 OpenGL이 작동하는 창을 띄운 뒤, 옆의 아무 PC로 가서 원격접속을 해보았더니 창이 그대로 떠 있고 OpenGL도 문제없이 구동되었었다. 그렇지만 원격접속 상태에서 창을 닫은 후 다시 실행하려면 되지 않았다. 즉, 원격 접속 상태에서 아예 불가능한게 아니라 처음 구동시킬 때의 계정이 원격접속 계정이면 안되게 막아놓았다는 점을 알 수 있었다.
d3.js 의 force layout은 네트워크 다이어그램을 볼 수 있는 강력한 툴이지만, 점의 갯수가 많아질 때 점과 선들이 한데 뭉쳐서 알아보기 힘들다는 단점이 있다. 이러한 단점을 해결하기 위해 여기서는 force layout을 확대축소할 수 있도록 코드를 수정하는 방법을 설명하겠다. force layout을 다루는 기본적인 방법은 알고 있다고 전제하였다.
이제 아래와 같이 zoom 과 pan이 가능해졌다. 이제 node들이 뭉쳐있는 곳을 확대해서 볼 수 있다.
그런데 문제가 있다. 점을 drag해보면 상당히 부자연스럽게 이동한다. drag할 때 node의 위치를 계산하게 되는데, zoom에 의한 xScale과 yScale 변화가 drag 부분에서 계산되지 않아서 발생하는 현상이다. 이 문제를 해결하기 위해 force에서 기본으로 제공하는 drag함수를 호출하지 않고 drag 함수를 재정의 하여 사용해야 한다. 위에서 zoom을 정의해준 부분 밑에 아래의 코드를 추가한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
//drag 함수를 새로 정의한다.
var drag = d3.behavior.drag()
.origin(function (d) { return d; }) //
.on("dragstart", dragstarted)
.on("drag", dragged)
.on("dragend", dragended);
// 드래그가 시작될 경우.
function dragstarted(d) {
d3.event.sourceEvent.stopPropagation(); //다른 이벤트 전달 중지




 nvidiaopenglrdp.zip
nvidiaopenglrdp.zip